Фреймворки: LangChain и LlamaIndex
В эпоху быстрого развития искусственного интеллекта большие языковые модели (LLM) произвели революцию в обработке естественного языка, но их изолированное использование часто оказывается недостаточным для сложных бизнес-задач.
Создание приложений поверх больших языковых моделей
Два фреймворка — LangChain и LlamaIndex — выделяются как мощные инструменты для создания сложных приложений поверх LLM. Эти фреймворки имеют встроенные интеграции с Ollama, что позволяет разработчикам использовать локальные модели в сложных пайплайнах, таких как RAG (Retrieval-Augmented Generation) и агентные системы.
Retrieval-Augmented Generation (RAG) — это передовая технология, которая позволяет LLM-приложениям подключаться к источникам данных конкретной предметной области, чтобы повысить точность и полезность ответов. RAG восполняет недостаток знаний у моделей, предоставляя им доступ к специализированной информации (например, внутренним данным организации), что особенно ценно, когда длительная тонкая настройка моделей невозможна из-за временных или финансовых ограничений.
Отдельная статья про RAG
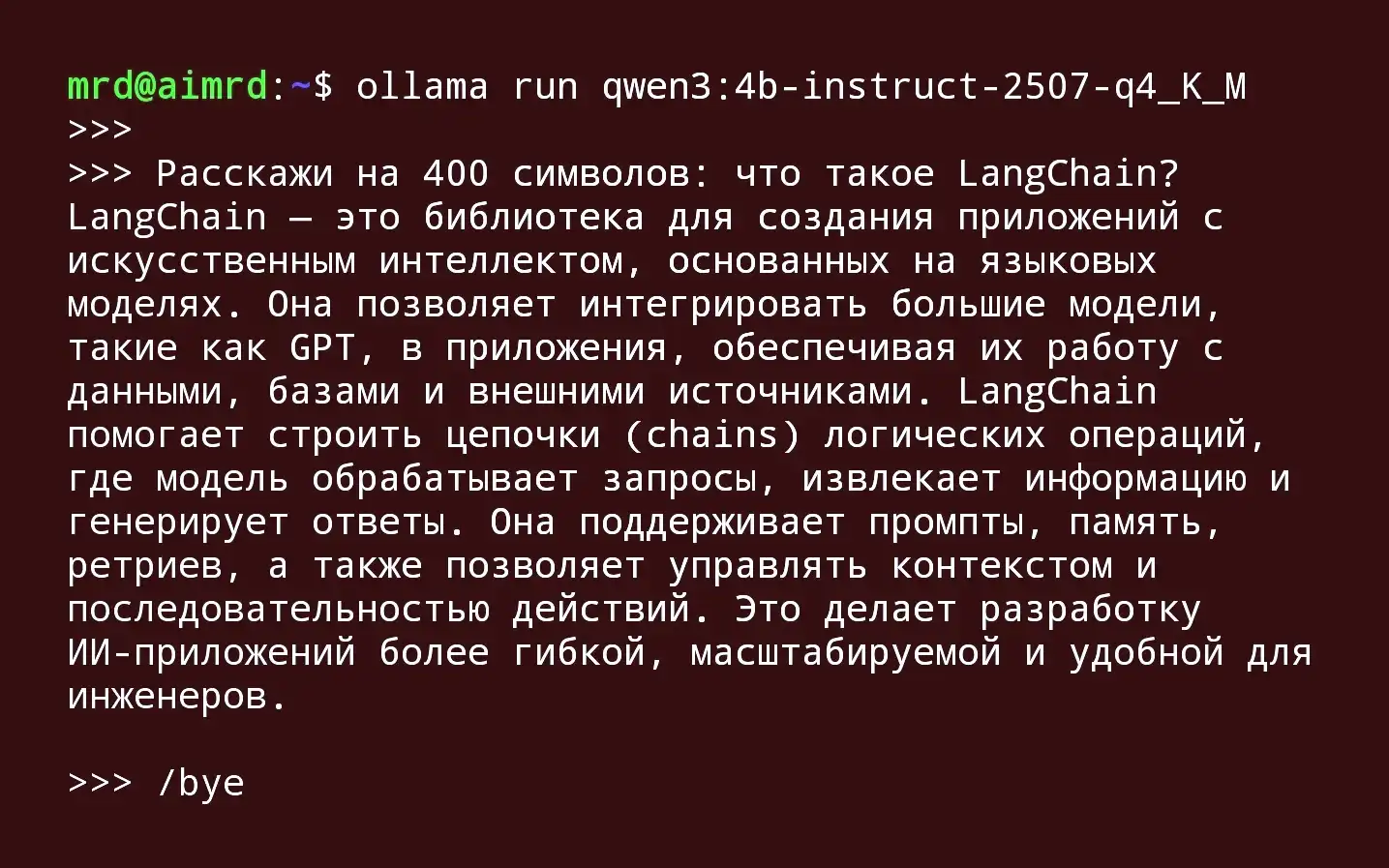
Что такое LangChain?
LangChain — это многофункциональный модульный фреймворк с открытым исходным кодом, предназначенный для создания сложных рабочих процессов и интерактивных приложений на основе LLM. Он предоставляет комплексный набор инструментов для создания и развертывания приложений, основанных на языковых моделях, поддерживая как Python, так и JavaScript.
Ключевые компоненты LangChain:
1️⃣ Модели: Унифицированный интерфейс для взаимодействия с различными LLM (OpenAI GPT, Anthropic Claude и др.) через API поставщиков.
2️⃣ Цепи (Chains): Объединяют несколько компонентов (например, моделей, подсказок, инструментов) для создания сложных многоэтапных рабочих процессов.
3️⃣ Память (Memory): Обеспечивает сохранение контекста между взаимодействиями, что критически важно для чат-ботов и длительных диалогов.
4️⃣ Инструменты (Tools): Функции, которые модели могут использовать для выполнения задач, такие как поисковые системы или вызовы API.
5️⃣ Агенты (Agents): Автономные модели, которые динамически определяют последовательность действий для выполнения задачи.
6️⃣ Интеграция данных: Поддерживает загрузку данных из множества внешних источников (Google Workspace, Figma, YouTube, базы данных).
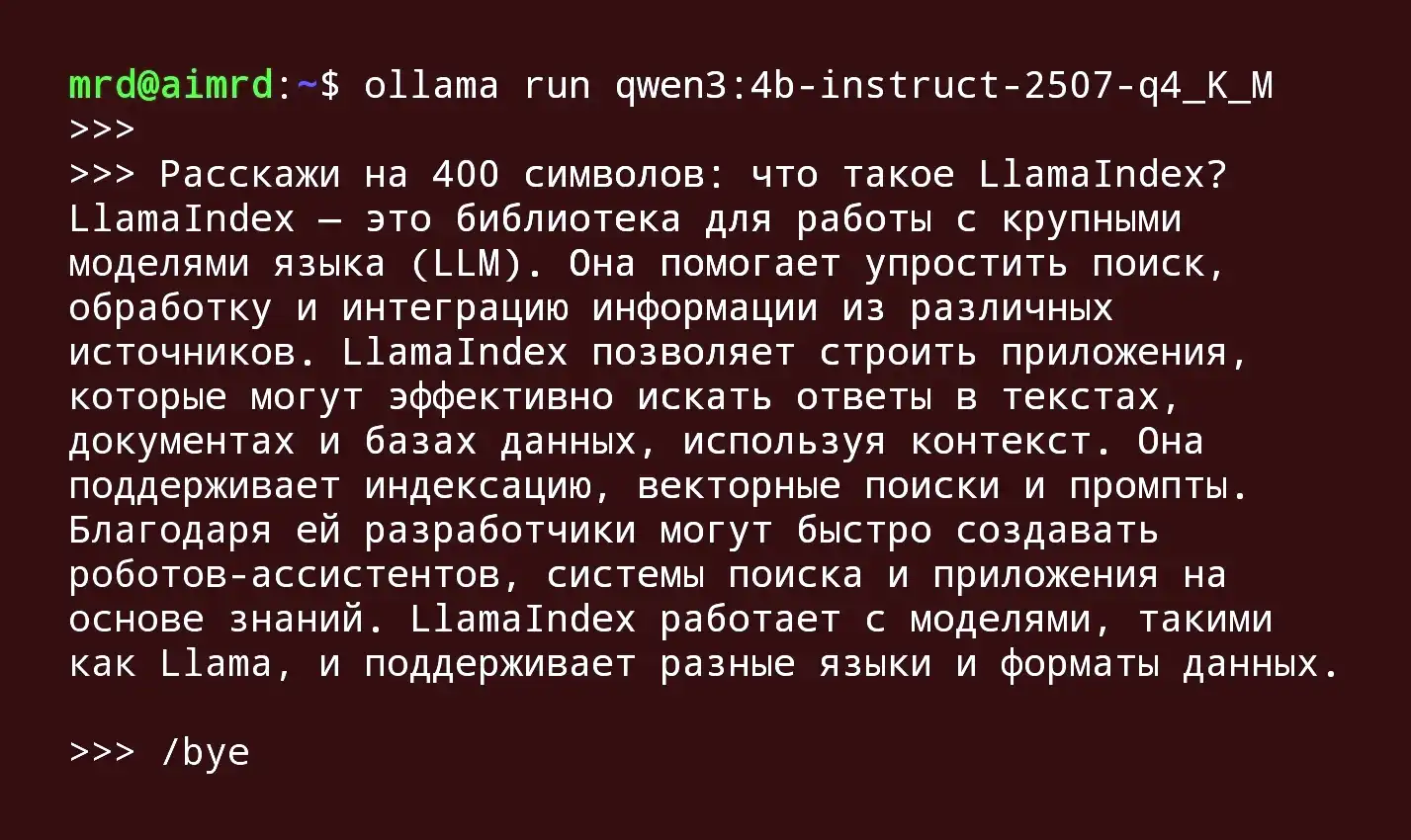
Что такое LlamaIndex?
LlamaIndex (ранее известный как GPT Index) — это специализированный фреймворк для индексации данных и поиска, созданный специально для оптимизации поиска и извлечения информации в RAG-системах. Он предоставляет эффективные инструменты для подключения LLM к большим наборам данных и создания приложений для извлечения информации.
Ключевые компоненты LlamaIndex:
1️⃣ Соединители данных (Data Connectors): Более 160 встроенных загрузчиков поддерживают структурированные, полуструктурированные и неструктурированные данные через LlamaHub (например, API, базы данных, документы).
2️⃣ Индексация данных: Автоматически преобразует пользовательские данные в эффективные векторные индексы с использованием моделей embedding, обеспечивая семантический поиск.
3️⃣ Запросы и извлечение: Использует расширенные алгоритмы поиска для точного извлечения наиболее релевантной информации.
4️⃣ Постобработка (Postprocessing): Повышает качество ответов за счет переупорядочивания и фильтрации извлеченных данных.
5️⃣ Синтез ответов (Answer Synthesis): Объединяет извлеченную информацию с пользовательским запросом и передает в LLM для генерации окончательного ответа.
Сравнительный анализ фреймворков
Таблица: Сравнение ключевых характеристик LangChain и LlamaIndex
| Критерий | LangChain | LlamaIndex |
|---|---|---|
| Основная направленность | Создание сложных, контекстно-ориентированных приложений | Эффективная индексация и поиск данных |
| Архитектура | Модульная, цепочная (chaining) | Центрированная вокруг данных, векторная индексация |
| Гибкость | Высокая, поддерживает сложные рабочие процессы | Умеренная, оптимизирована для поисковых задач |
| Контекстное взаимодействие | Продвинутое управление памятью | Базовая поддержка контекста |
| Сложность обучения | Более крутая кривая обучения | Пологий подъем, удобство для новичков |
| Идеальные сценарии использования | Чат-боты, агенты, многозадачные рабочие процессы | Поиск в базе знаний, вопросно-ответные системы |
Сильные и слабые стороны
LangChain превосходит конкурентов, когда требуется высокая степень кастомизации и сложная агентная логика. Его модульная архитектура позволяет разработчикам создавать сложные цепочки действий, интегрировать множественные источники данных и инструменты. Однако эта гибкость сопровождается более сложной кривой обучения.
LlamaIndex специально создан для эффективного поиска и извлечения информации, что делает его идеальным для RAG-приложений. Он предоставляет высокоуровневые API, которые упрощают и ускоряют создание поисковых систем поверх пользовательских данных. Однако его возможности за пределами поиска и извлечения ограничены по сравнению с LangChain.
Интеграция с Ollama для работы с локальными моделями
Ollama — это легковесный фреймворк, который упрощает развертывание и управление большими языковыми моделями на локальных машинах. Он предоставляет интуитивно понятный API, совместимый с OpenAI, и набор предварительно сконфигурированных и оптимизированных моделей (таких как Llama 2, Mistral, Gemma), готовых к использованию на потребительском оборудовании.
Статьи про Оллама
Преимущества использования локальных моделей через Ollama:
- Конфиденциальность: Данные остаются на локальных машинах, что критически важно для работы с конфиденциальной информацией.
- Экономия: Отсутствие затрат на API-вызовы к внешним моделям.
- Гибкость: Возможность работы без подключения к интернету.
- Производительность: Оптимизированные (квантованные) версии моделей позволяют эффективно работать даже на CPU.
Оба фреймворка — и LangChain, и LlamaIndex — имеют встроенные интеграции с Ollama, что позволяет разработчикам легко включать локальные модели в свои пайплайны.
Практические применения и варианты использования
С LangChain
- Сложные диалоговые системы: Виртуальные ассистенты и служба поддержки, требующие долгосрочного сохранения контекста.
- Автономные агенты: Системы, которые могут динамически планировать и выполнять задачи, используя различные инструменты.
- Многомодальные приложения: Интеграция различных источников данных (видео, API, базы данных) в единый рабочий процесс.
С LlamaIndex
- Вопросно-ответные системы для внутренних баз знаний: Быстрый поиск в корпоративных документах, технической документации.
- Анализ нормативных документов: Обработка структурированных и иерархических документов в юриспруденции, здравоохранении.
- Системы рекомендаций на основе контента: Семантический поиск похожего контента.
Комбинированный подход
Во многих сценариях LangChain и LlamaIndex могут использоваться вместе, объединяя свои сильные стороны. Например, можно использовать LlamaIndex для эффективной индексации и извлечения данных, а затем передавать результаты в сложные рабочие процессы LangChain для дальнейшей обработки, интеграции с внешними инструментами или принятия решений.
Заключение
LangChain и LlamaIndex предлагают различные, но взаимодополняющие подходы к созданию приложений поверх больших языковых моделей. LangChain выделяется своей гибкостью и способностью создавать сложные, контекстно-ориентированные приложения, тогда как LlamaIndex оптимизирован для эффективного поиска и извлечения информации в RAG-системах.
Интеграция обоих фреймворков с Ollama открывает возможности для развертывания мощных AI-приложений на локальной инфраструктуре, что особенно важно для организаций, работающих с конфиденциальными данными или имеющих ограниченный бюджет.
Выбор между фреймворками зависит от конкретных требований проекта:
- Для сложных интерактивных приложений с богатым контекстом предпочтительнее LangChain.
- Для эффективных поисковых систем и быстрого внедрения RAG лучше подходит LlamaIndex.
- Для максимальной производительности в сложных сценариях можно комбинировать оба фреймворка.
По мере развития экосистемы LLM оба фреймворка продолжают расширять свою функциональность, предлагая разработчикам все более мощные инструменты для создания интеллектуальных приложений следующего поколения.
Опубликовано:
Популярное на сайте

